Scaling
Scaling controls that keep performance and cost in balance
Tune resources, scale manually, or let Wodby autoscale your services and clusters as demand changes.
Scaling should not mean overprovisioning for every possible spike. Wodby gives teams a practical set of controls for application capacity, from service-level CPU and memory limits to autoscaling rules and cluster growth when workloads need more room.
Set service-level resource controls before scaling becomes urgent
Good scaling starts with clear CPU and memory boundaries for each workload.
Wodby lets you tune resource requests and limits per service so busy components do not crowd out everything else in the cluster. This creates a more stable baseline, makes costs easier to reason about, and gives autoscaling rules better inputs to work from later.
Autoscale app services from real demand
When traffic changes, the platform can adjust replica counts instead of leaving teams to react by hand.
Define minimum and maximum replica counts, connect them to utilization targets, and let Kubernetes add or remove capacity as traffic moves. This keeps applications responsive during spikes while avoiding the cost of leaving extra replicas running all the time.
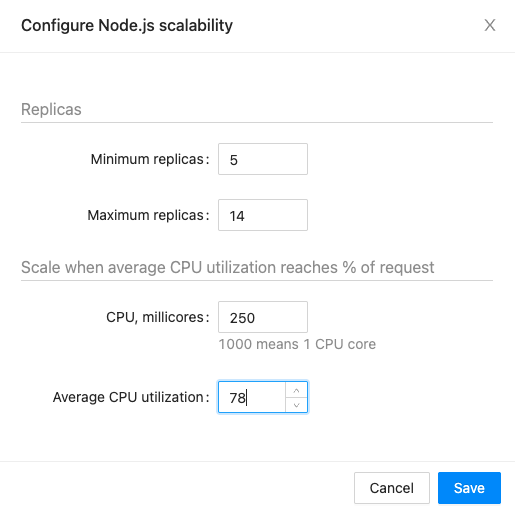
- Protect customer-facing services during unexpected traffic surges.
- Reduce spend during quiet periods without changing deployments.
- Keep scaling rules close to the rest of your application settings.
Keep manual scaling available for planned events
Not every workload needs automation all the time.
Teams can still scale services manually for launches, campaigns, migrations, or maintenance windows. That is useful when you already know demand will change and want to prepare capacity ahead of time.
Grow cluster capacity when applications need more room
Application autoscaling works best when the cluster layer can expand with it.
Through Wodby's Kubernetes integrations, clusters can add or remove nodes based on actual demand. That helps teams avoid the common failure mode where applications want to scale but the cluster has nowhere to place the new workloads.
Plan for bigger workloads as vertical scaling evolves
Some applications need larger service footprints, not just more replicas.
Vertical scaling support is planned for cases where increasing CPU or memory on an existing workload makes more sense than adding replicas. That will expand the scaling toolbox for stateful and specialized services that do not fit horizontal scaling cleanly.
Next step
Scale only when the workload actually needs it
Give teams a clear path from baseline resource tuning to autoscaling and cluster growth without layering extra tooling around Kubernetes.